

Youtube
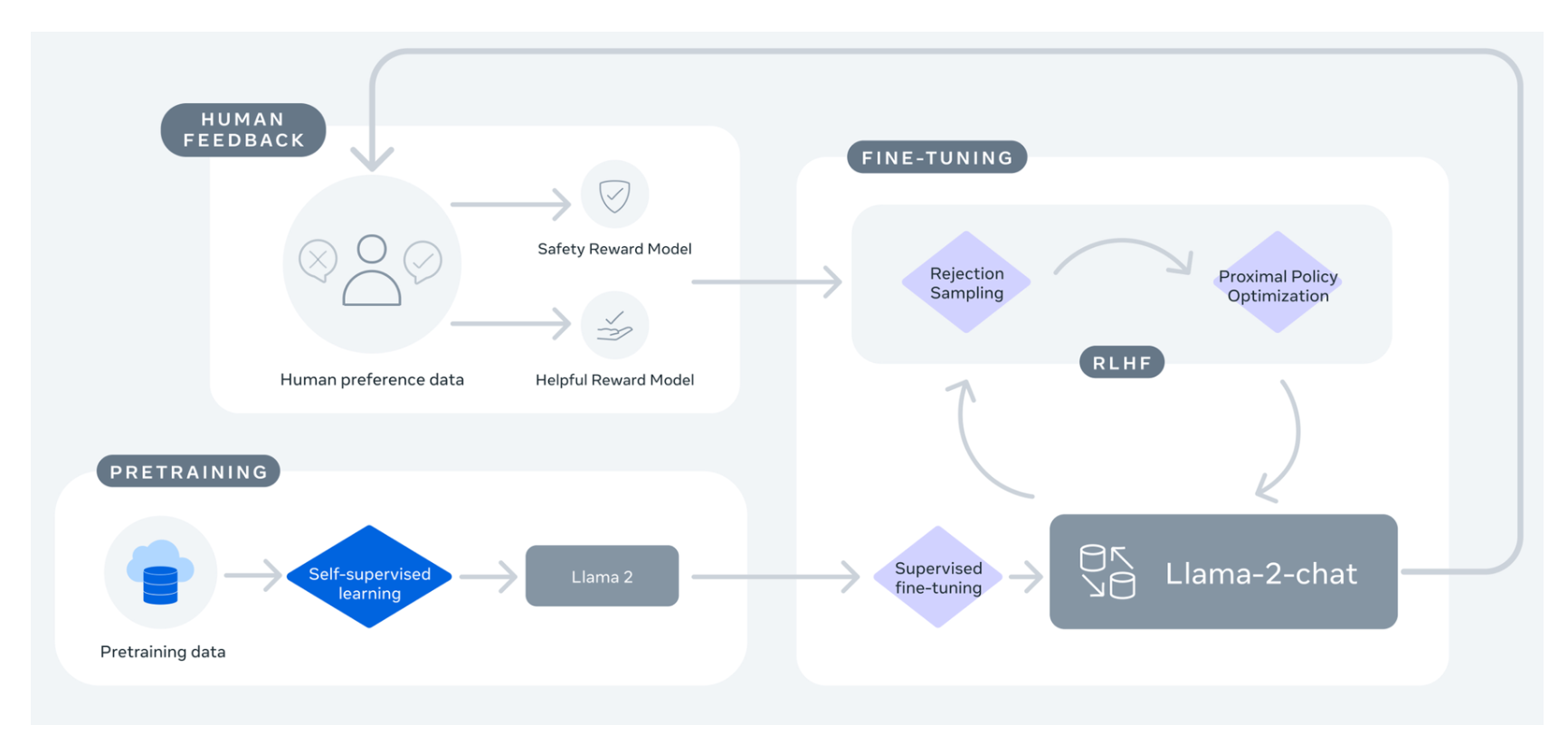
WEB In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. WEB Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters Our fine-tuned LLMs called Llama-2-Chat are. WEB Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the launch with comprehensive integration in Hugging. WEB To deploy a Llama 2 model go to the huggingfacecometa-llamaLlama-2-7b-hf relnofollowmodel. WEB Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters This is the repository for the 70B pretrained model..
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Web We release Code Llama a family of large language models for code based on Llama 2 providing state-of-the-art performance among open models infilling capabilities support for large. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Web In this work we develop and release Llama 2 a family of pretrained and fine-tuned LLMs Llama 2 and Llama 2-Chat at scales up to 70B parameters On the series of helpfulness and safety. Web We introduce LLaMA a collection of foundation language models ranging from 7B to 65B parameters We train our models on trillions of tokens and show that it is possible to train state..
Github
Result Understanding Llama 2 and Model Fine-Tuning Llama 2 is a collection of second-generation open-source LLMs from Meta. In this notebook and tutorial we will fine-tune Metas Llama 2 7B. Parameter-Efficient Fine-Tuning PEFT with LoRA or QLoRA. Result torchrun --nnodes 1 --nproc_per_node 4 llama_finetuningpy --enable_fsdp --use_peft --peft_method lora. In this notebook and tutorial we will fine-tune Metas Llama 2 7B..
Fine-tune Llama 2 with DPO a guide to using the TRL librarys DPO method to fine tune Llama 2 on a specific dataset Instruction-tune Llama 2 a guide to training Llama 2 to generate instructions from. This blog-post introduces the Direct Preference Optimization DPO method which is now available in the TRL library and shows how one can fine tune the recent Llama v2 7B-parameter model on the stack. The tutorial provided a comprehensive guide on fine-tuning the LLaMA 2 model using techniques like QLoRA PEFT and SFT to overcome memory and compute limitations By leveraging Hugging Face libraries like. In this section we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2 on simple hardware and show how to fine-tune the 7B version of Llama 2 on a single NVIDIA T4 16GB -. This tutorial will use QLoRA a fine-tuning method that combines quantization and LoRA For more information about what those are and how they work see this post In this notebook we will load the large model..



Comments